
Introduction
Today’s vector search uses five orders of magnitude more compute than BM25, the leading retrieval algorithm in 1994. We ask the question: How good can retrieval get if we use another five orders of magnitude more compute? We train SID-1 to answer this question.
We apply multi-turn, multi-environment reinforcement learning (RL) to Qwen3-14B, training on a mixture of synthetic and real questions. Our RL environments build on the idea that humans with search tools can find almost any information given sufficient iteration. Humans make a first search, read the results, and adapt their strategy.
This back-and-forth addresses the issues that many single-turn pipelines face (RAG): They are structurally unable to answer queries that require reasoning over results or executing multiple steps. Approaches exist to address these shortcomings with human-designed mechanisms such as reranking or workflows. We posit that replacing human design with compute is fundamentally what drives SID-1 to outperform these mechanisms.
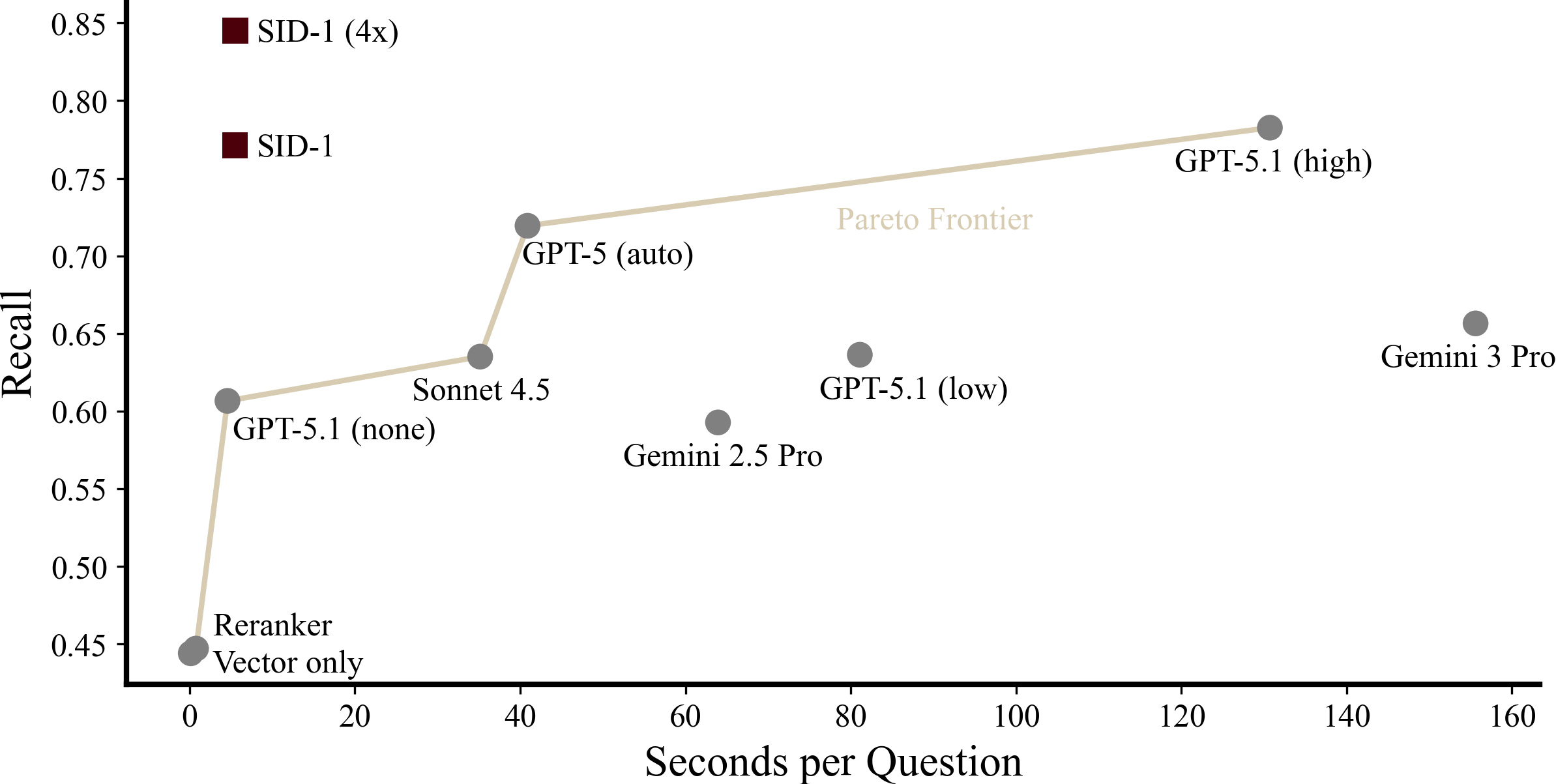
Figure 1a: Performance versus time per question (calculated). Top/left is best. SID-1 (4x) scores fuse results from four parallel rollouts. Please see the results section for more details on evaluation.
Our key contributions are:
- SID-1 is the first model trained specifically for agentic, closed corpus retrieval across general knowledge, finance, science, legal, and email. We discuss reward design, challenges with multi-turn reinforcement learning infrastructure, and chart a path to training models without human cold start data.
- SID-1 (4x) achieves 0.84 recall – a 1.9x improvement over embedding with reranking (0.45) while maintaining better precision. It outperforms agentic retrieval implemented using Gemini 3 Pro, Sonnet 4.5, and GPT-5.1 on it's highest compute setting. Please see results for details and other metrics.
- Fast and efficient: SID-1 is 24x faster than GPT-5.1 (high) (6 vs 144 seconds per question) and 7x faster GPT-5 (auto). Making it the only practical model at the performance frontier. The model adapts effort to question difficulty, recovering latency and tokens for easy questions. Our most expensive model, SID-1 (4x) is 374x lower cost than Sonnet 4.5 ($0.0006/question vs. $0.41 for Sonnet 4.5) when self-hosted.
- Composable: SID-1's reward design allows it to work as a subagent with larger LLMs, much like swe-grep for coding agents.Introducing SWE-grep and SWE-grep-mini: RL for Multi-Turn, Fast Context Retrieval (Pan et al., 2025) SID-1 can use existing search tools and does not require changes to the search algorithm or expensive reindexing.
- Customizable: Our synthetic question pipeline allows training to retrieve over any corpus without human question data. We chronicle lessons from making training more stable and designing great training questions.
Scaling
We examine performance scaling along two dimensions, model size and the number of training tasks. We use our evaluation dataset of diverse, challenging retrieval queries and report results in terms of Normalized Discounted Cumulative Gain (NDCG). We measure the performance uplift delivered by our reinforcement learning pipeline.
As model size increases, we observe a gradual, approximately logarithmic improvement in base model retrieval quality (Figure 2). Applying our RL pipeline consistently yields a substantial performance boost, corresponding to a greater than 10x effective compute multiplier.Compute Multipliers (Betker, 2023)
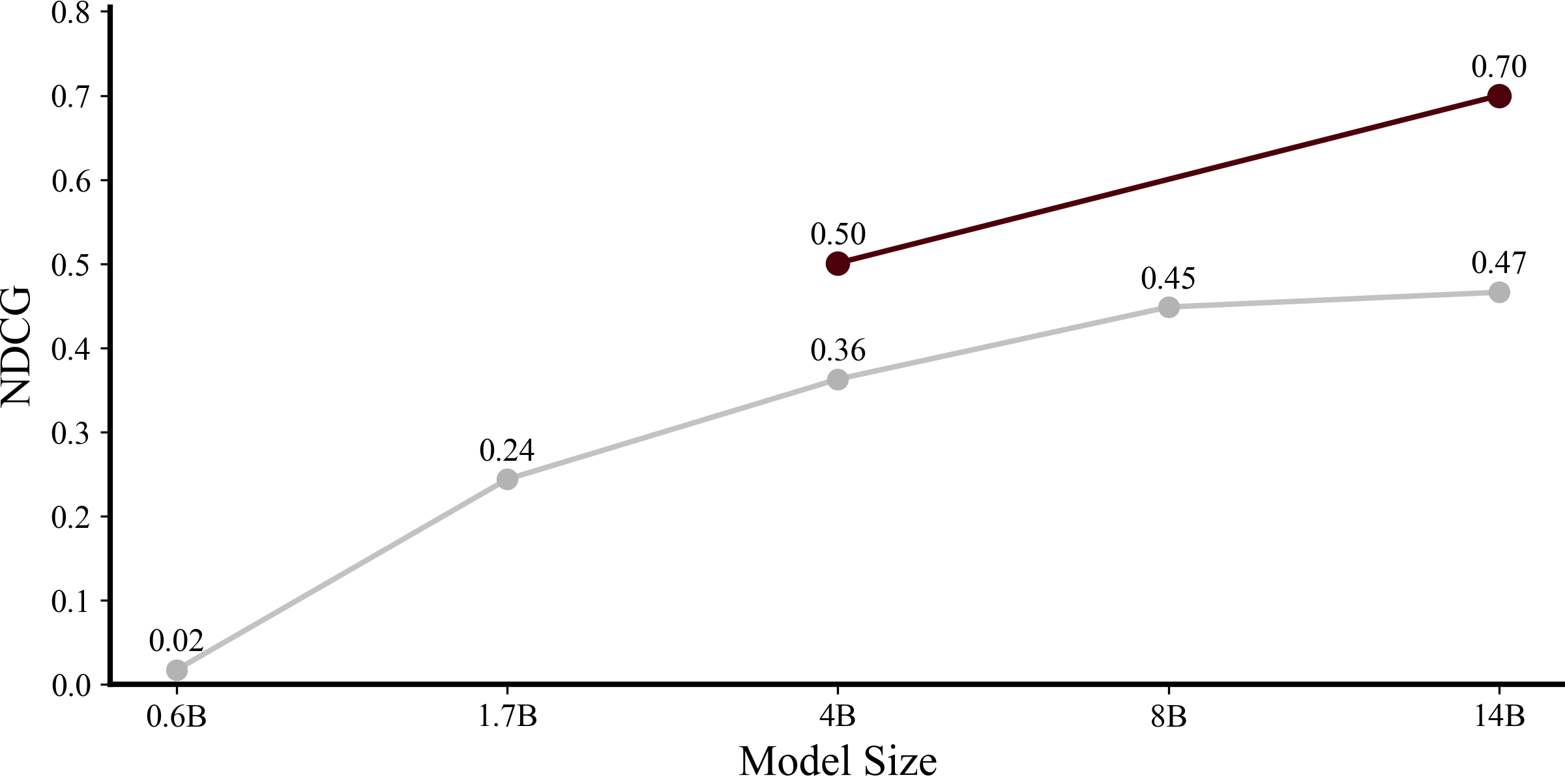
Figure 2: Performance of the Qwen3 series of models on our evaluation set (gray), along with the performance uplift from using our RL pipeline (red). We only evaluate RL for 4B and 14B models.
In Figure 3, we report that scaling the number of retrieval tasks and thus training compute also leads to a smooth performance increase. Retrieval performance (NDCG) has an approximately log-linear relationship with training compute expended, with room for improvement given more compute. After our comparatively modest training compute expenditure, our model beats much larger frontier models at the task of retrieval.
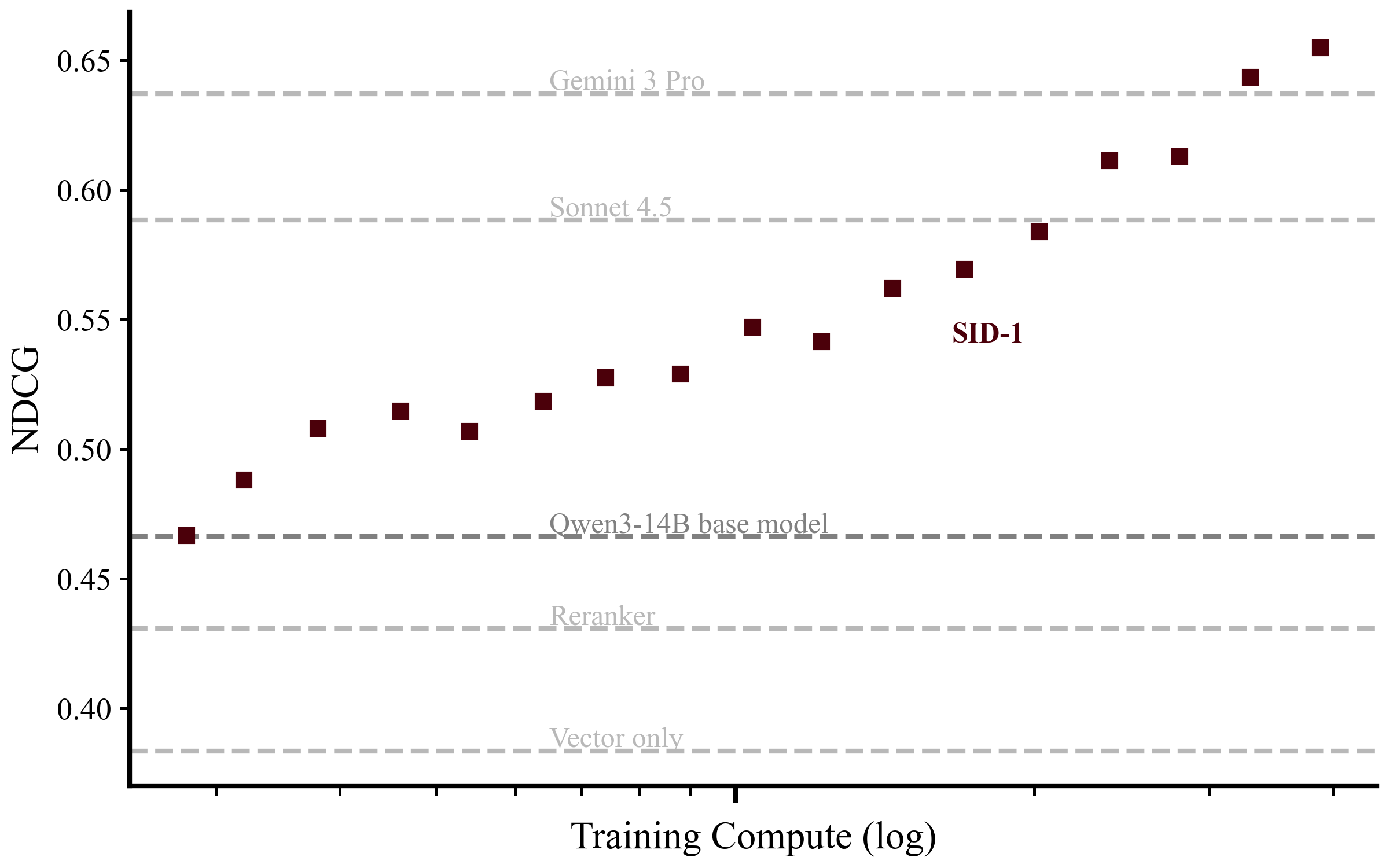
Figure 3: Performance of SID-1 (red) as we scale the number of retrieval tasks in training. Baselines for our base model as well as frontier models in agentic retrieval and embedder/reranker pipelines shown in dashes.
We see no intrinsic ceiling to our achievable retrieval performance. We can scale by another 3-6 orders of magnitude with more environments, questions per environment, and model size – without any algorithmic improvements or infrastructure changes. As the agentic setting is compatible with any tool, we can also extend environments to include structured retrieval like SQL.
Rewards
We define our task as:
Given a question and a set of search tools, report the documents needed to answer the question ordered by relevance.
Notably, this setting is different to Search-R1 and OpenAI's SimpleQA. These require the model to report the answer to the question, which is then compared using exact string matching or an LLM-as-a-judge.
Our document-centric approach has four advantages:
- Separates searching from synthesis: Our task decouples retrieval competence from downstream answer generation.
- Composability: Returning documents rather than synthesized answers allows SID-1 to function as a sub-agent in larger systems or power an existing search bar.
- Fine-grained reward signal: Partial credit can be assigned when the model finds some but not all relevant documents.
- Robustness to memorization: A model might answer correctly from pretraining knowledge alone, bypassing search entirely. By requiring documents rather than answers, we ensure the model must actually use its search tools (see Training section for more detail).
Accuracy
Comprehensiveness of retrieval upper-bounds performance of an AI system as a whole: an infinitely powerful downstream model can solve a task if given all the correct documents, even with a few irrelevant documents, but cannot solve a task if one crucial document is missing. We thus believe that overreporting by a few documents is preferable to underreporting by one. We believe that the practical drawbacks of overreporting can also be mitigated by ordering, which has the benefits of aiding downstream models in identifying the most relevant reported documents and enabling an end user with strict context window management requirements to simply take the first k documents retrieved.
Recall and precision – although widely used for evaluation of retrieval pipelines – are hackable metrics for training. The recall-optimal strategy is to report all documents seen in any order. The precision-optimal strategy is to report the single document assessed to most likely be a target document. While F-1 (or F-Beta) balances the two, it still is indifferent to ordering of the reported documents.
Our primary training metric is NDCG Cumulated gain-based evaluation of IR techniques (Järvelin, Kekäläinen, 2002), which scores a ranked document list based on how well it approximates the ideal ordering. It naturally discourages gross over-reporting: while the model is still incentivized to include relevant documents, the marginal gain diminishes with rank, unlike in recall-based training.
We calculate NDCG as follows: Assume the model returns an ordered list of documents . We use binary relevance: let be the set of relevant (target) documents, and write for the indicator that position contains a target document.
Format
We initially train without format rewards. As accuracy rewards are conditional on using the (tool calling) format correctly, we believe models should learn the format without further intervention. This notion was further supported by our base models format pass rate being extremely high (>0.95) for our group size, ensuring that there is a training signal even in step zero.
Unfortunately, we observed persistent regressions in format adherence in later stages of training, leading us to introduce format rewards. In future work, we want to study using an SFT model with great format adherence instead.
Training
SID-1 was trained using Magistral’s modified version of GRPO without SFT. In the sections below, we chronicle a few important algorithmic and infrastructure observations discovered in development.
Tokens-In/Tokens-Out
Many reinforcement learning frameworks use OpenAI-style messages for their environment interaction. This has many benefits, such as being able to use the inference engines’ inbuilt tool call parsers and compatibility with API-models for SFT data generation.
Messages are practicable for offline RL, single-turn environments, or settings which use few chat template features (no thinking, no tool calling, for example). For multi-turn environments with many tool calls, using the messages abstraction invariably leads to model collapse. Parsing a token list to a message list is lossy. For example, it erases whitespace information around tool calls. Applying the chat template to generate the next turn then subtly changes the tokens. When inspecting logprobs, we observe extremely unlikely tokens where these shifts occurred (see example in Figure 4).
Figure 4: Log probabilities of tokens for a trained 14B model in a non-TI/TO respecting pipeline. At rollout time, the byte sequence " \" is generated as two tokens, which gets transformed into one extremely low probability token after retokenization.
Training on these tokens leads to instability and collapse over time. We trace this collapse to feedback loops:
- At generation time, the model produces two categories of rollouts, (ood) and (ad) rollouts, for example rollouts could have incorrectly formatted tool calls.
- Passing the bad rollouts from the generation engine to the training engine causes them to appear like good rollouts: .
- At training time, the model sees with negative advantage, whereby some tokens in have extremely negative logprobs and thus dominate the gradient, driving these logprobs even more negative and the model to generate fewer good rollouts in general.
We find this explains the gradual performance increase followed by catastrophic collapse patterns observed in prior work, which we depict in Figure 5.Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning (Jin et al., 2025) We find that simply ensuring that all rollouts are processed by our pipeline in a strictly Tokens-In/Tokens-Out (TI/TO) manner is sufficient to prevent these extreme training instabilities without the use of importance sampling ratios.Your Efficient RL Framework Secretly Brings You Off-Policy RL Training (Yao et al., 2025)
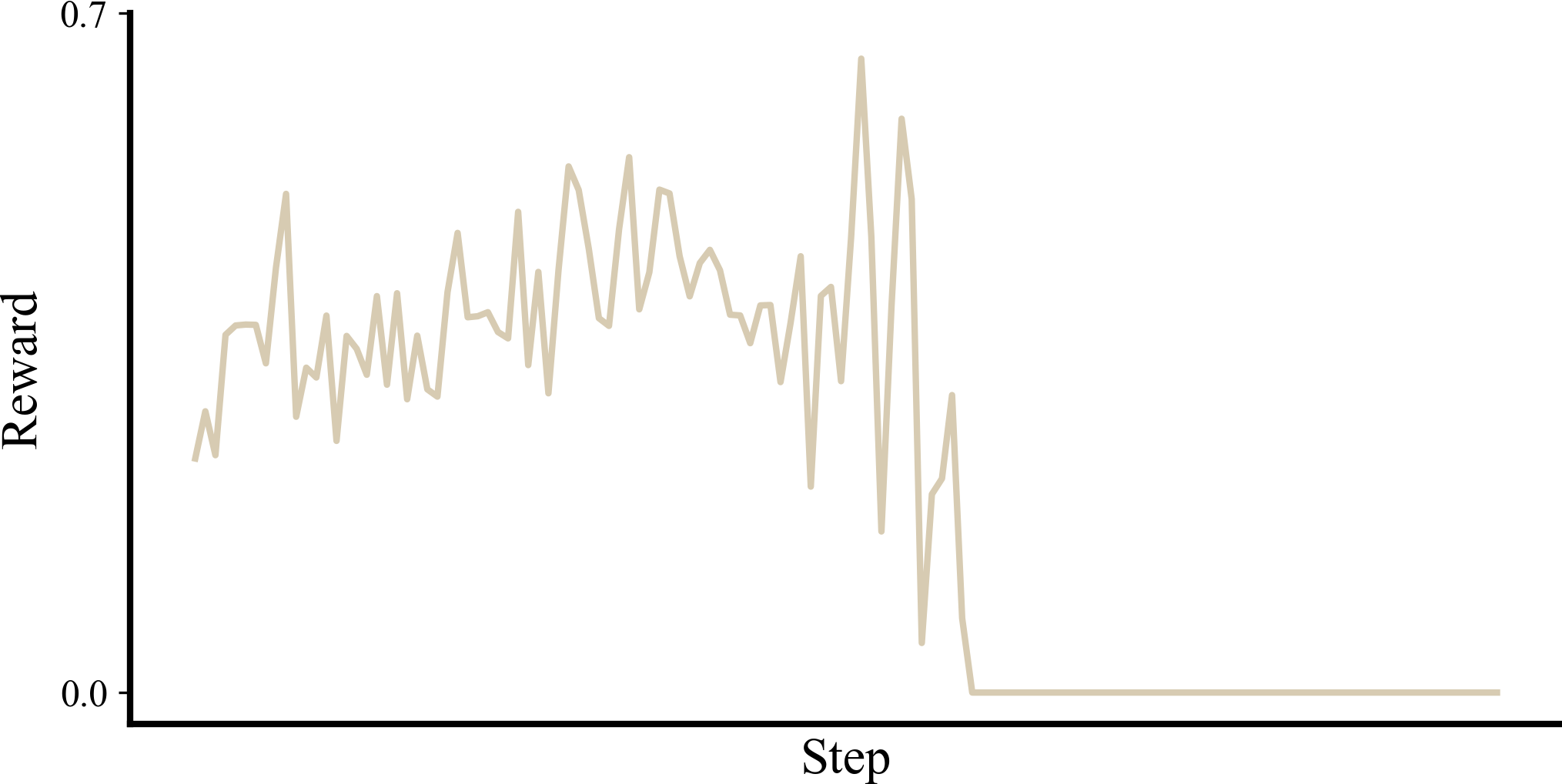
Figure 5: Training on malformed tokens sees reward increase initially. After some time, we observe a decrease in tool calling accuracy followed by fully degenerate outputs. This collapses the reward and is not recoverable.
Length Normalization
Dr. GRPOUnderstanding R1-Zero-Like Training: A Critical Perspective (Liu et al., 2025) observes that per-sequence length normalization incentivizes the model to find shorter positive advantage and longer negative advantage rollouts. To alleviate this "length bias" they normalize per group instead. MagistralMagistral (Mistral AI, 2025) and most RL frameworks follow this approach.
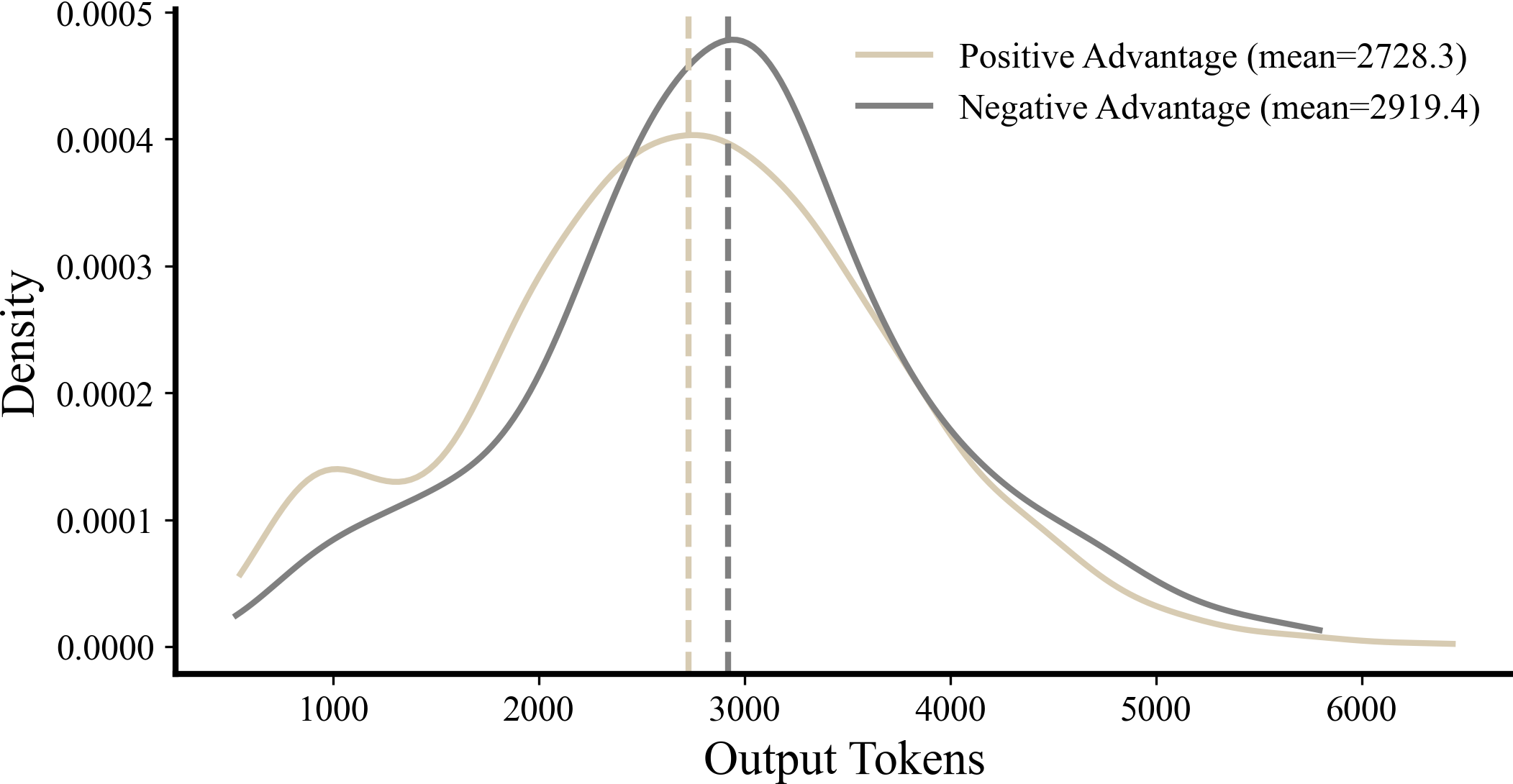
Figure 6: Length distribution for positive and negative advantage rollouts (1848 rollouts, model-generated tokens only). Negative advantage rollouts are generally longer.
We find experimentally that removing the length bias leads to unreliability over long training runs. Specifically, we observe the model starts producing out-of-vocabulary tokens. We posit the following root cause: By removing the length bias, the mean per token advantage is no longer guaranteed to be zero. As negative advantage rollouts tend to be longer, the mean per token advantage is negative, which we depict in Figure 6. This suppresses the logits of allocated tokens globally; over time, as assigned logit values collapse, the model begins to sample allocated tokens from the tokenizer's vocabulary (which are included as embedding matrix dimensions are rounded to have a high power of 2 factors). This regression appears robust to hyperparameters, and we prove that the gradients flowing to the logits of these unallocated tokens will be positive if the advantage has this length bias removed.
Let be the -th token of the -th rollout and be the length of rollout . We can formulate both the standard and length-debiased GRPO in the same objective formula by defining the following per-token advantages from the raw advantages :
Length-biased:
Unbiased:
Either of these can be put into the objective formula below to achieve the GRPO surrogate policy objectives:
Lemma 1: For length-debiased GRPO, the between the sequence length and the raw advantage is proportionate to the sum of the per-token advantages , in particular they share the same sign.
Proof. We can calculate:
This shows that if there is a negative between the lengths of rollouts and their advantages, we should expect for the per-token advantage term to be negative. Intuitively, we can see that this would depress and thus increase the probability of rare tokens, and we will see that this can be made into a precise statement.
Lemma 2: In expectation, has a negative linear relationship to the gradients of logits of unsampled (out-of-vocabulary) tokens with respect to the GRPO objective under necessary assumptions.
Proof. We will treat the case of being exactly on-policy, i.e. so that the derivatives of the per-token loss can be treated as the derivatives of a log-policy-likelihood:
Suppose that the probability distribution for a specific token is defined by the softmax of some vector of logits and that the logit corresponding to an out-of-vocabulary token (not equal to ) is . Calculating the derivative of the sample objective with respect to this logit gives:
Crucially, the derivative of log-softmax is always positive and independent of the selected token , as long as this token is not the out-of-vocabulary token itself. Taking expectations over this token, conditioned on it not being out-of-vocabulary:
Together, these lemmas draw a clear path from negative between the lengths of rollouts and their advantages, to being on average negative, to the logits of unsampled tokens being increased when is maximised with backpropagation.
Length Scheduling. We find that compute is optimally allocated throughout the training run by starting at a low maximum length for rollouts which is gradually increased over time. We also leverage a soft length penaltyMagistral (Mistral AI, 2025),CWM: An Open-Weights LLM for Research on Code Generation with World Models (FAIR CodeGen team, 2025) to enable retrieval and length-based training signals to be propagated from the same rollout.
Parallel tool use and hierarchical retrieval. In Figure 7 we show that our model learns to use multiple tools in parallel without further intervention. This reduces end-to-end latency by reducing the number of round trips to the retrieval server. We also introduce hierarchical retrieval, loosely inspired by the web search tools in gpt-ossgpt-oss-120b & gpt-oss-20b Model Card (OpenAI, 2025) and OpenPipe art-e.ART·E: How We Built an Email Research Agent That Beats o3 two times (Corbitt, 2025) The initial search only provides short excerpts from the documents. If the model wants to read the full content, it can selectively "read" the document by using a read tool. This architecture reduces token usage and allows the model to see more documents before exhausting context window limits. For many questions, this lets SID-1 use fewer input tokens than reranking.
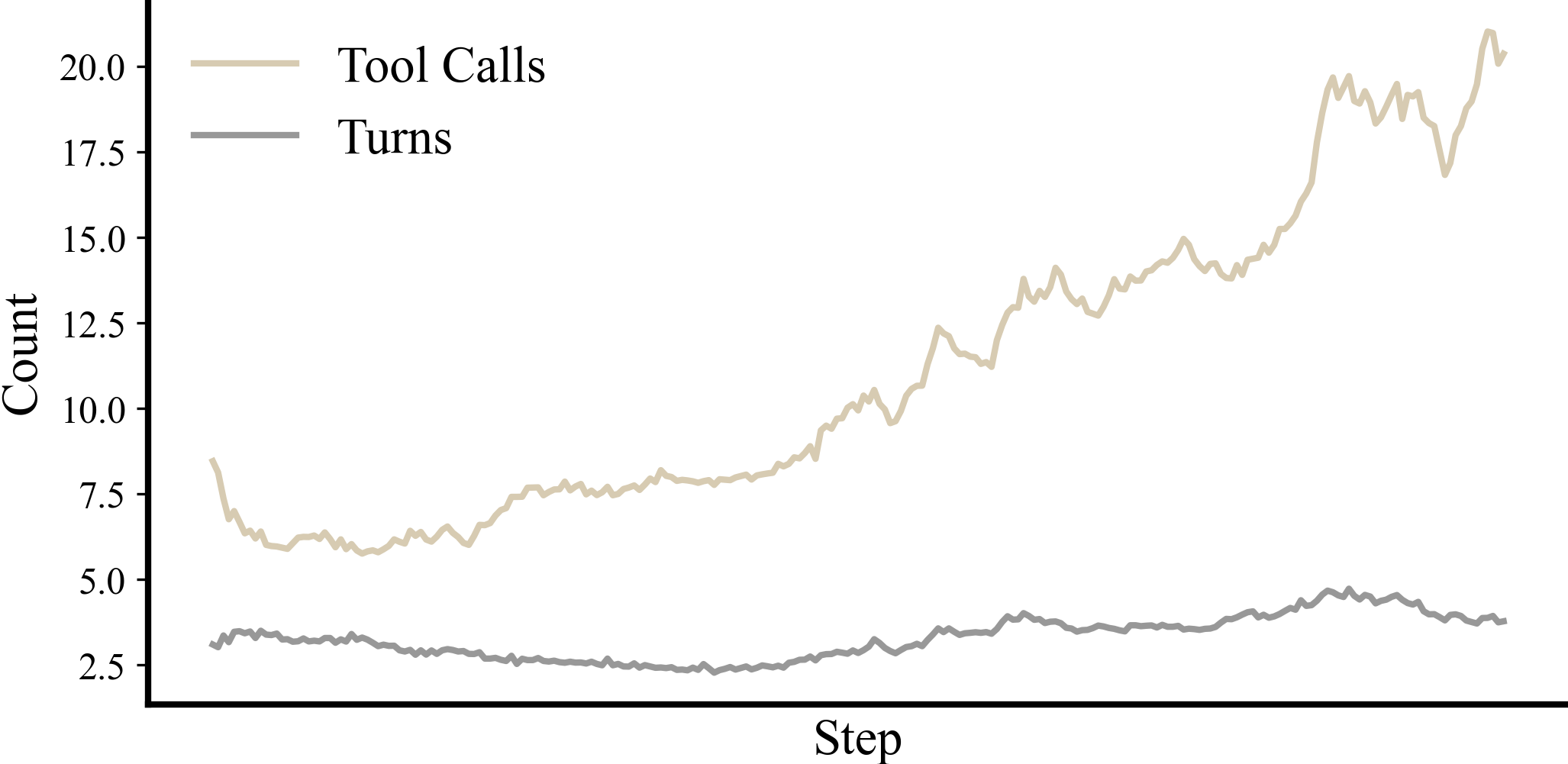
Figure 7: The turn count stays constant while the number of tool calls increases, showing that our model learns to make multiple search requests per turn. More tool calls per turn are desirable, as it decreases round trips to the retrieval backend.
Data
SID-1 is designed as a general retrieval model. We use corpora spanning general knowledge, science, finance, legal, and email HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering (Yang et al., 2018) WWW'18 Open Challenge: Financial Opinion Mining and Question Answering (Maia et al., 2018) Fact or Fiction: Verifying Scientific Claims (Wadden et al., 2020) A Reasoning-Focused Legal Retrieval Benchmark (Zheng et al., 2025) ART·E: How We Built an Email Research Agent That Beats o3 two times (Corbitt, 2025). All corpora are written by humans. We design an RL environment for each corpus to support specialized search operations, like filtering by date on emails.
Question Specificity
For each corpus , we have a set of questions . Each question has a corresponding set of target documents . These target documents are defined to be necessary and sufficient to answer the question. Because we source from public datasets, humans, and synthetic generation, the target documents might be erroneous. To study these errors, we also define the theoretical golden , which is our ideal, error-free list of target documents. is unknown and we have no general way to derive . When a question has no errors, is equal to .
We identify the following sources of errors:
- (most common): The target documents contain unnecessary documents. This incentivizes the model to report spurious documents, reducing precision.
- : There are some relevant documents in the corpus that are not in the target documents. This makes the reward sparser and adds noise to the signal (if your reward considers the order of documents).
- and : The question is unanswerable with the documents in the corpus.
Questions with empty are filtered from the training dataset and are not a source of error. It is possible that the intersection is not equal to one of the sets, but these samples behave like (1) and (2) from a training perspective, so we do not break them down further.
An illustrative example for an error of type (1) is the following HotpotQAHotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering (Yang et al., 2018) question: "Which actor does American Beauty and American Beauty have in common?" with target documents titled "American Beauty (soundtrack)" and "American Beauty (1999 film)." Only the latter answers the question. The soundtrack was not sung by any actor starring in the movie. (The question is also somewhat nonsensical, which is emblematic of the generally poor quality of public QA datasets).
Measuring errors is extremely difficult because is unknown. However, we can study the effects of some of these errors by observing training behavior. For example, in datasets that suffer from (1), the model starts reporting spurious documents way above the actual number of target documents. Figure 8 shows training on a public dataset we know to be noisy from manual inspection. Compared to a training run on our synthetic questions, which are subject to checks to reduce errors.
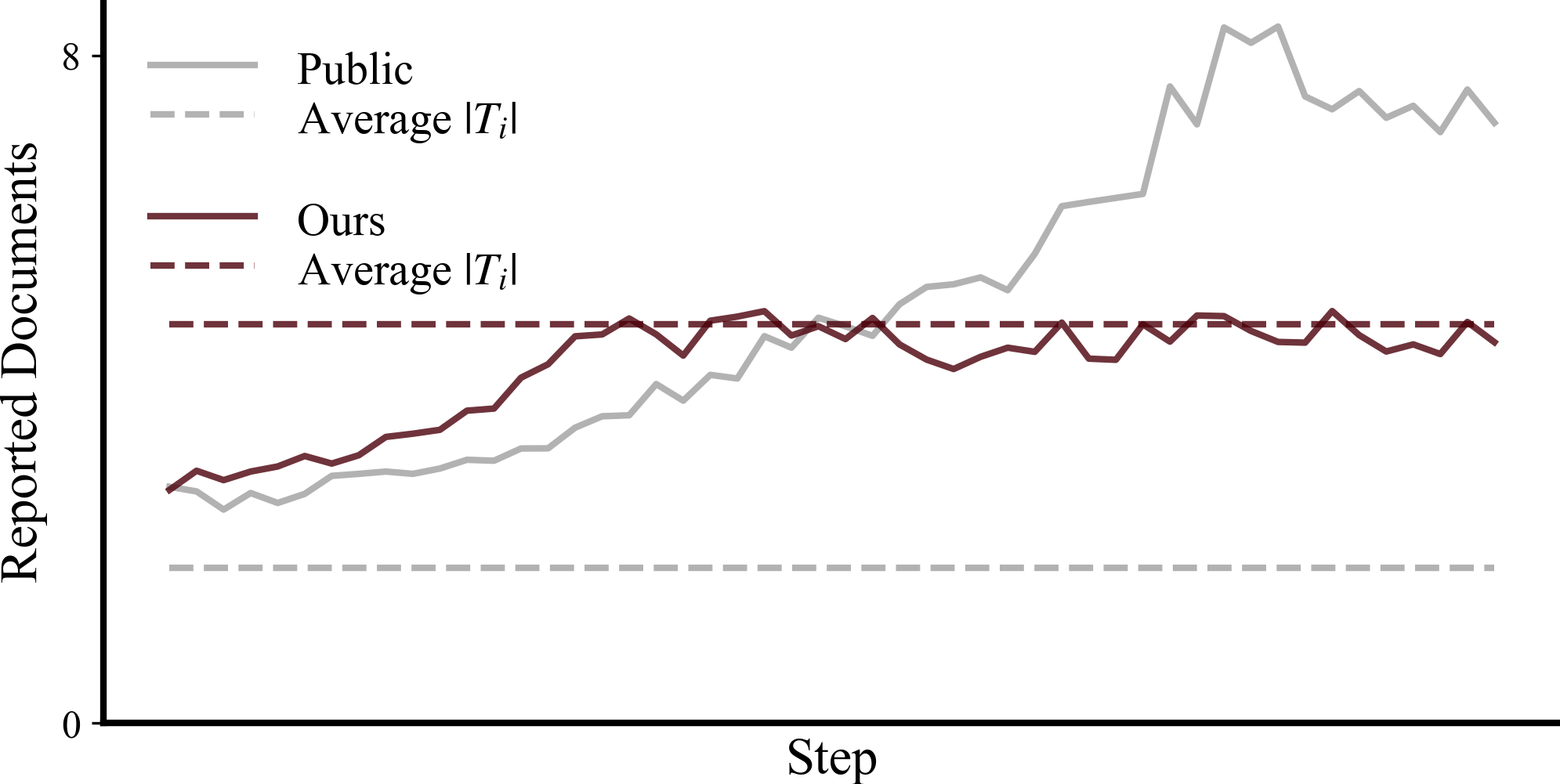
Figure 8: Training on questions that have noisy target documents (Public) incentivizes the model to overreport documents in hope of catching spurious targets. The number of documents reported quickly grows much larger than the true average number of target documents. We compare this against training on our synthetic questions, which we subject to checks to reduce noise: The number of reported documents quickly converges to the true number of target documents.
Given , (1) is the easiest error to control for as it only requires reasoning over the question and the target documents and we do this heavily. (2) and (3) are much harder as they require reasoning across the entire corpus. BrowseCompBrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents (Wei et al., 2025), which retrieves over the internet, mentions error (2) explicitly but chooses to simply accept it. Given our corpora are much smaller than the internet, we find that it is still possible to correct (2) and (3) heuristically. We reserve chronicling these heuristics for future work.
Synthetic Generation
Given the low quality of public retrieval datasets, we expand training to use synthetically generated questions. We differentiate between two kinds of (synthetic) questions:
Single-hop questions can be answered using a single search query, for example “What is the capital of France?” These questions are generated by picking a random document from the corpus and prompting an LLM to write a question about that document. Generally, single-hop questions are trivial for most models and provide little training signal (if a group receives all perfect scores, the GRPO advantage is all zero). Attempts to make single-hop questions harder almost always introduce one of the errors. For example, we try rewriting the document first, removing key words, and adding personas.Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models (Zhang et al., 2025)
Multi-hop questions require multiple searches that reason about the results found. These are much harder for the model to solve. We believe this is a realistic setting for closed corpus retrieval: As closed corpuses are small, the chance that a given question has a perfect answer is vanishing. Answering a question often requires piecing together multiple documents that already exist.
FRAMESFact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation (Krishnaet al., 2025) generates multi-hop questions by leveraging the hyperlink structure between Wikipedia articles. This approach is limited to corpora with explicit inter-document links, a feature rarely present in real-world document collections. To overcome this limitation, we construct links dynamically using document-to-document similarity, enabling multi-hop question generation on arbitrary corpora. The majority of our synthetic questions use this approach. An example question generated this way is:
What's the age gap between
the TV producer who created the soap that premiered on the same night a major UK channel launched
and
the Prime Minister who represented the producer's hometown in Parliament?
We note that the ability to generate hard multi-hop questions is a recent emergent capability in large language models. Attempts by this team in 2023 and 2024 largely failed to generate sufficiently diverse questions for training.
Verification. We subject the question and the designated target documents to a further round of LLM judging to minimize error (1). We also enforce that the target documents contain the seed document randomly taken from the corpus. We find that if the model is allowed to write a question without seed, it will not produce diverse questions.
Customization. Being able to generate hard questions for any corpus allows us to train customized models without the need for expensive human-labelled data. This is especially useful for domains where the highest levels of accuracy are required.
Multi-epoch training. The model is asked to report the documents by reporting their unique identifiers (IDs). To prevent the model from memorizing the IDs across epochs, we obfuscate the IDs before passing them to the model. We train a 4B parameter model for 100 epochs on a 100 question subset of our training mix and find continual eval improvement, with only a minimal performance degradation compared to never repeating. Memorization is still possible through remembering the content of the document, but we find only minimal evidence for this when inspecting the rollouts.
Results
We test SID-1 on a custom benchmark consisting of 191 questions across general knowledge, finance, science, legal, and email. Around half of these questions (91) are sourced from publicly available retrieval benchmarks. The other half (100) are custom designed, manually-reviewed, and generally much more challenging (multi-step, multi-hop). Importantly, we manually design these questions using a different pipeline than used to generate our training questions, mandating that our model must generalize.
Scores
We evaluate two realistic settings for SID-1: A single rollout (1x) and four rollouts with reciprocal rank fusion (RRF) (4x). In the 4x setting, we let the model perform 4 rollouts in parallel with a slightly increased temperature. We then fuse the list of reported documents using RRF. As these four rollouts are independent and thus fully parallel, this comes at almost no increased latency.
Our embedding model is Qwen3-Embedding-0.6B. All LLMs use the same retrieval backend for fairness. To evaluate the retrieval only setting, we embed the question directly and find the ten closest documents by vector similarity. Reranking uses MXBAI Rerank Large v2 hosted by Together AI as a scoring model: We retrieve the 30 closest documents, pass them to the reranking model and evaluate the ten highest-scoring documents. We note that the Together AI API erroneously inverts the scores when using the parameter. Thus, we do not use the parameter but evaluate the raw scores instead.
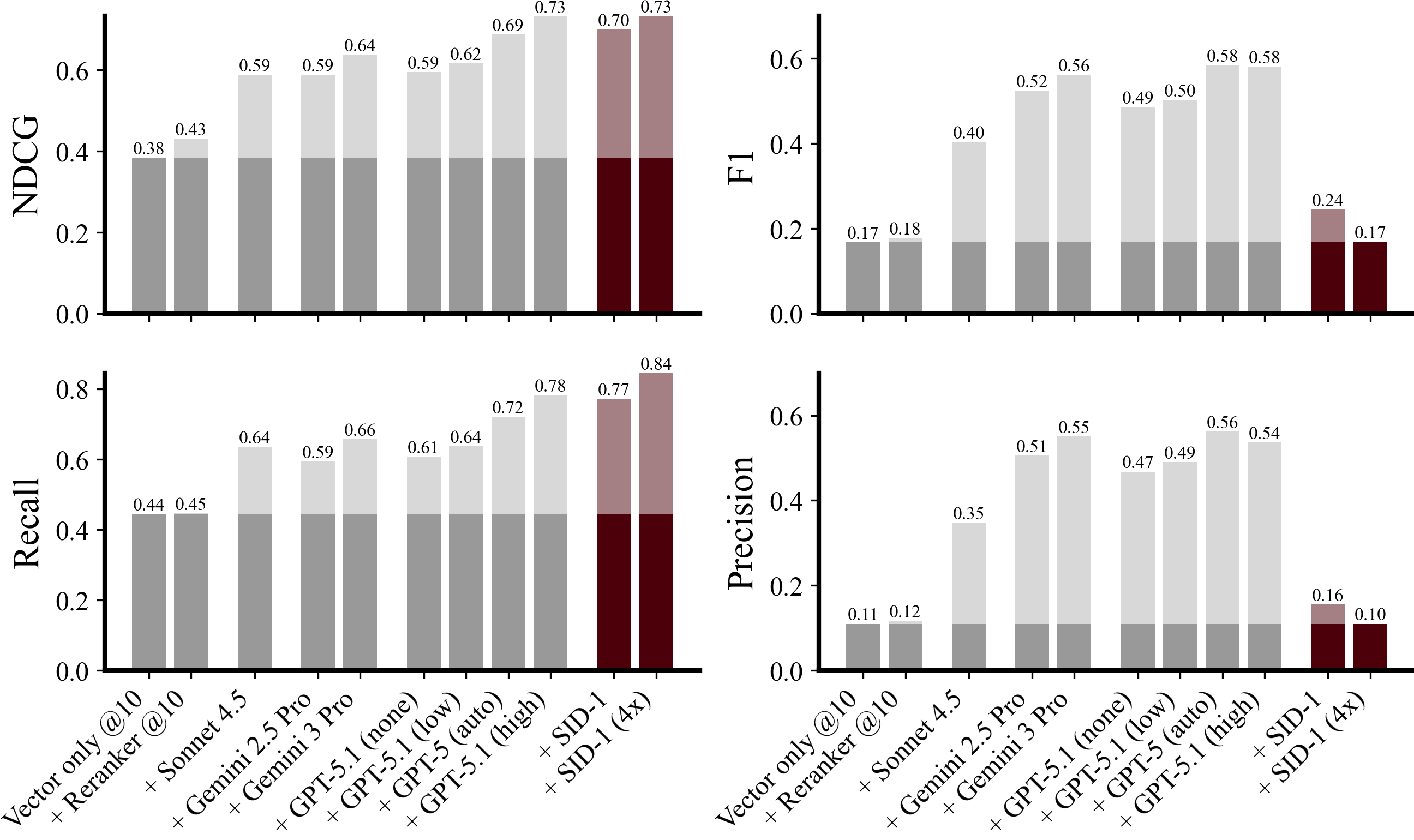
Figure 9: Benchmark performance for different model families. Higher is better. Dark corresponds to retrieval only performance. Light is the uplift from adding an agentic LLM. SID-1 (4x) outperforms all LLMs on NDCG (0.73) and matches the best performance for recall. As we incentivize slight overreporting during our training, our precision (and thus F1 score) are slightly lower, but still outperform vector-only and reranking.
We choose to compare SID-1 with the largest and most capable frontier LLMs and not LLMs of comparable serving cost (like GPT Nano or Gemini Flash Lite). While SID-1 delivers drastic cost and speed improvements, we are most interested in raising the ceiling of what retrieval performance is possible.
SID-1 has the highest recall out of all models tested. Recall measures what share of correct documents were found and reported by the model. SID-1 (4x) has the highest recall with 0.84, followed by GPT-5.1 (high) with 0.78 and SID-1 1x with 0.77. We find that Anthropic and Google models underperform across the board. Vector-only finds around half as many correct documents.
SID-1 (4x) achieves the highest NDCG. SID-1 (4x) achieves 0.73 NDCG, on par with GPT-5.1 (high). NDCG rewards finding the correct documents and placing them in the correct order (most relevant first). SID-1 1x achieves 0.7 NDCG, also outperforming GPT-5 (auto) at 0.69.
Precision and F1. Precision measures how many of the reported documents are correct. We train SID-1 to overreport slightly, as we believe omission of important information to be more costly in downstream applications than adding superfluous documents. This naturally reduces SID-1’s precision and thereby F1 score (which is the harmonic mean of recall and precision) – a tradeoff we willingly make. SID-1 still maintains a higher precision and F1 score than vector-only and reranking.
Speed. SID-1 is 24x faster than GPT-5.1 (high) and 7x faster than GPT-5 (auto), the models most similar in retrieval scores (6, 144, and 41 seconds respectively). Getting to sub-10s latency enables agentic retrieval in latency critical applications, such as voice AI or synchronous AI assistants, for the first time. The only technique significantly faster than SID-1 is vector-only retrieval, which delivers subsecond latencies. But as retrieval results are canonically passed to a large LLM for synthesis (RAG), which has latency in the (tens of) seconds, going from 5s to 0.1s retrieval only delivers a marginally better end-user-experience.
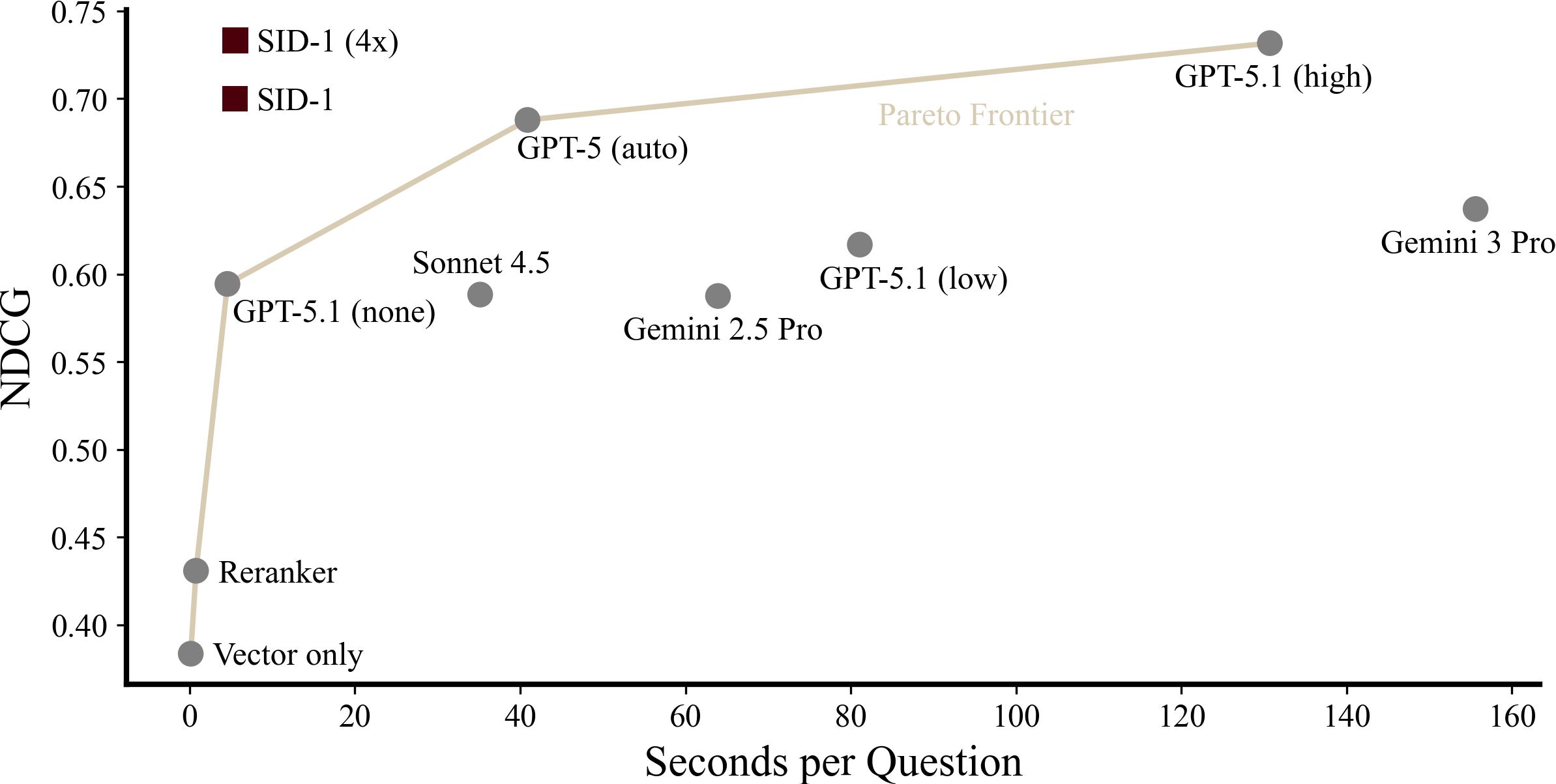
Figure 10: NDCG versus time per question (calculated). Top/left is best. We use the real token usage and calculate the time using Artificial Analysis (for API models) and vLLM multi-turn benchmarks on 2xH100 for Qwen3-14B (ours, 140 tokens/s). Reranker time is measured using MXBAI Rerank Large v2 served by Together AI. We find calculations give better estimates, as wall clock time has extreme variance across providers and would unnaturally benefit SID-1 (which runs more predictably on our hardware).
Cost. SF Compute, the only infrastructure provider with pricing for Qwen3-14B (SID-1’s base model), charges $0.04/0.15 per 1M input/output tokens. At this price, SID-1 1x is 585-920x cheaper per question than GPT-5 and Sonnet 4.5 respectively. It is cheaper than reranking on Together AI. Train-time efficiency techniques explain a 5-10x decrease in costs (hierarchical retrieval, parallel tool calling, using fewer turns). The other 100x are explained by lower per token costs. SID-1 pricing will almost certainly be higher than this, given we would cease to exist if they were lower.
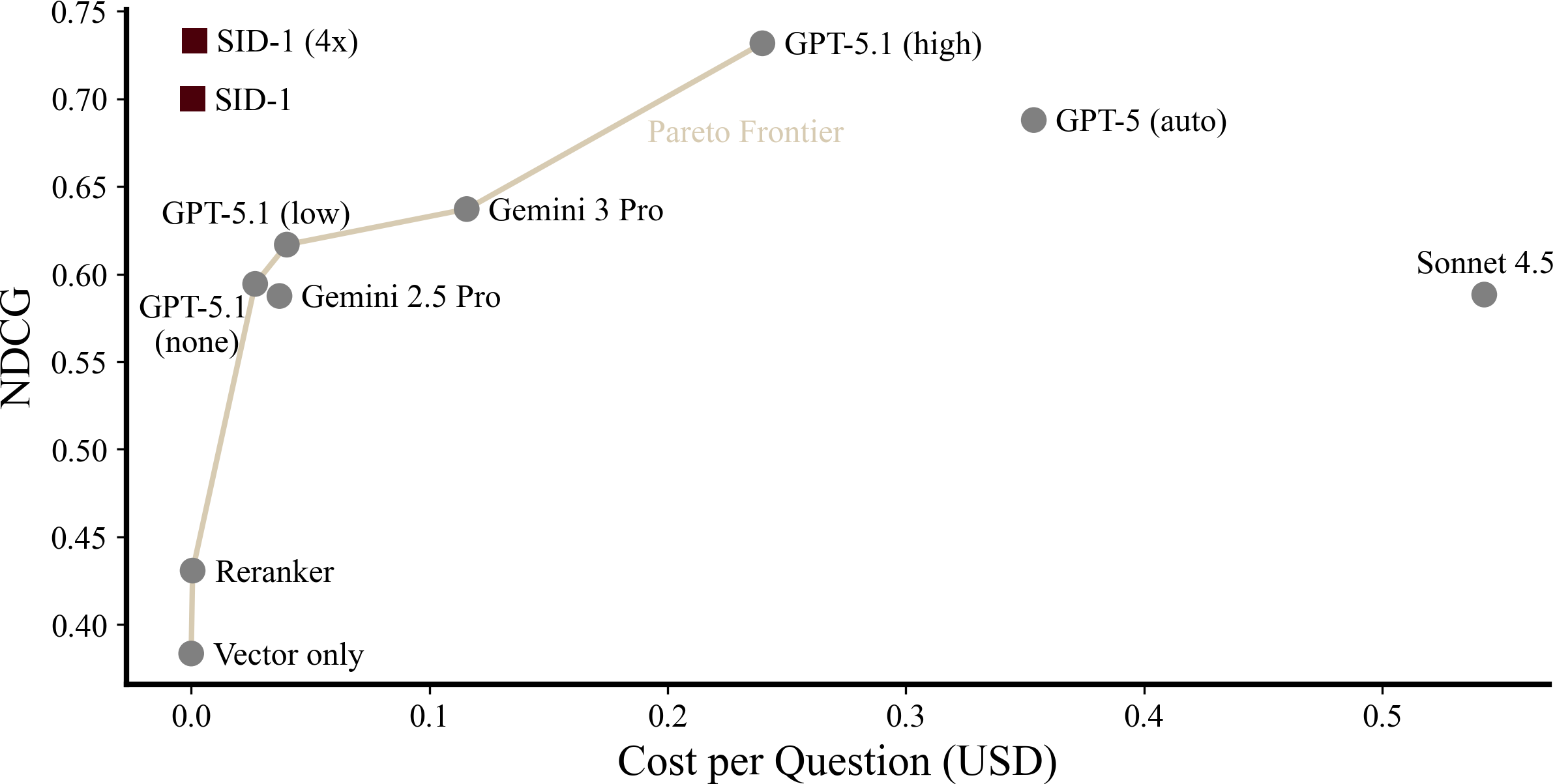
Figure 11: NDCG versus cost per question (USD). Top/left is best. We use real token usage and first-party API pricing, as well as SF Compute for cost estimates for serving base Qwen3-14B. The reranker is MXBAI Rerank Large v2 served by Together AI. Embedding cost is estimated with OpenAI text-embedding-3-large.
Retiring academics. SID-1 and the GPT-5 series saturate some academic retrieval benchmarks like HotpotQA and Scifact. We analyze performance on a subset of 20 randomly selected questions from HotpotQA and Scifact and find almost perfect NDCG for both SID-1 and GPT-5. For the agentic setting, we propose retiring these benchmarks entirely. Our custom benchmarks remain difficult even when using frontier LLMs.
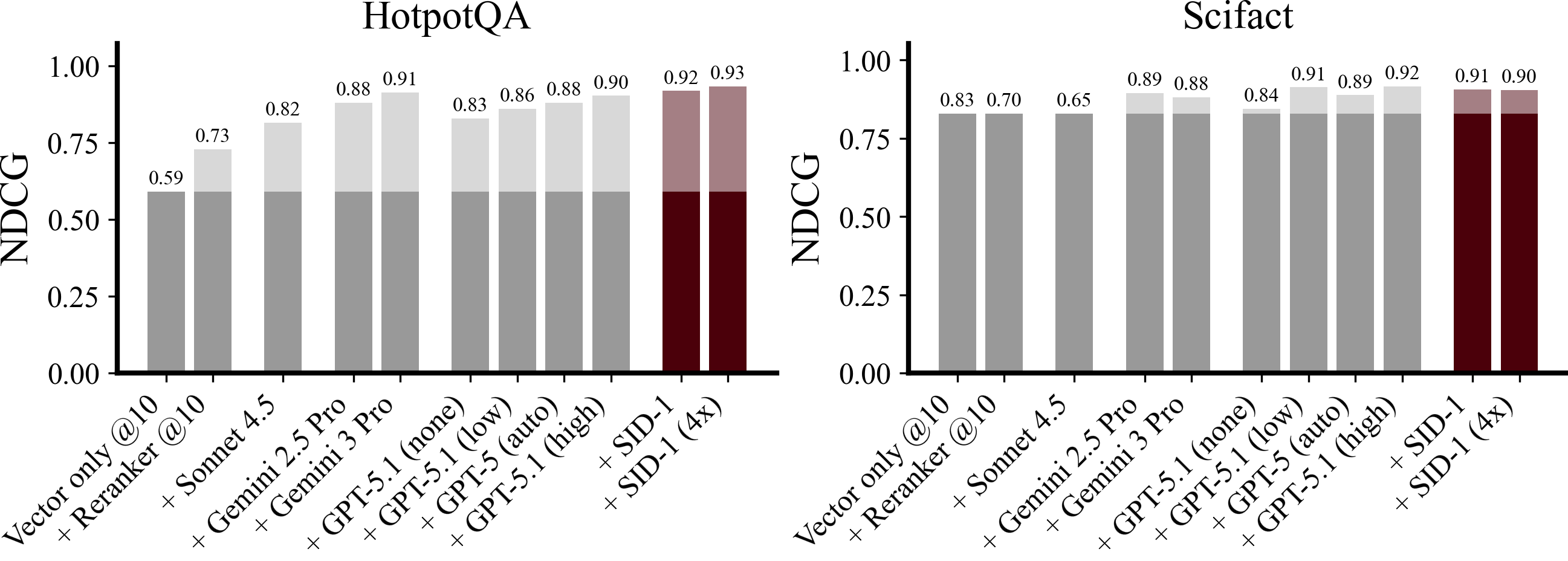
Figure 12: Agentic approaches achieve almost perfect NDCG over 20 randomly selected questions from HotpotQA, Scifact. Both datasets have high levels of label noise.
Conclusion
We have shown that agentic retrieval delivers a step-change improvement in retrieval quality, delivering both increased scores on (academic) benchmarks and making new kinds of questions solvable (multi-step, multi-hop). SID-1 sets a new benchmark in retrieval quality, reduces the cost of agentic retrieval by 3-4 orders of magnitude, and does it 1-2 orders of mangitude faster than frontier LLMs. As posited, SID-1 achieves this with minimal human design: no prescribed pipelines or SFT.
Citation
Please cite this work as:
Research Team, "SID-1 Technical Report: Test-Time Compute for Retrieval",
SID AI, Dec 2025.
Or use the BibTeX citation:
@article{sid2025preview,
author = {SID Research},
title = {SID-1 Technical Report: Test-Time Compute for Retrieval},
journal = {SID AI},
year = {2025},
note = {https://www.sid.ai/research/SID-1-technical-report}
}